Dokumentasi Project Fadhil - Cat Whisperer
Memprediksi Kondisi Kucing berdasarkan Vokalisasi dengan Deep Learning
Gini caranya menggunakan Deep Learning untuk mengklasifikasikan suara kucing
Pengantar
Manusia telah berhasil meraih bintang-bintang, namun masih berjuang untuk memahami teman-teman kucing kita.
Dengan kumpulan dataset meong kucing kita dapat berkontribusi pada tugas yang relevan ini dan berupaya untuk menerjemahkan meong mereka — sehingga mereka dapat secara resmi memberi tahu kami bahwa kami sebenarnya adalah hewan peliharaan mereka.
Tujuan
Dengan dataset Cat Meow Classification | Kaggle. Kelompok Fafi Mami (Fathur, Fadhil, Marcelino Mamahit) membuat model untuk mengklasifikasi suara meong kucing sebagai usaha untuk lebih mengerti bahasa yang dibicarakan kucing sehingga manusia dapat merawat kucing lebih baik.
Dataset
Kumpulan data (Dataset) ini, terdiri dari 440 rekaman suara, berisi suara meong yang dikeluarkan oleh kucing dalam konteks yang berbeda. Secara khusus, 21 kucing yang termasuk dalam 2 ras (Maine Coon dan European Shorthair) telah berulang kali terkena tiga rangsangan berbeda yang bertindak sebagai label untuk prediksi:
- Menunggu makanan;
- Isolasi di lingkungan yang tidak dikenal;
- Menyikat (disikat dengan penuh kasih sayang oleh pemiliknya).
Konvensi penamaan untuk file -> CNNNNNBBSSOOOOO_RXX, di mana:
- C = konteks emisi (nilai: B = Brushing; F = Waiting For Food; I: Isolation in unfamiliar environment);
- NNNNN = ID unik kucing;
- BB = breed (nilai: MC = Maine Coon; EU: European Shorthair);
- SS = jenis kelamin (nilai: FI = betina, utuh; FN: betina, dikebiri; MI: jantan, utuh; MN: jantan, dikebiri);
- OOOOO = ID unik pemilik kucing;
- R = sesi perekaman (nilai: 1, 2 atau 3)
- XX = penghitung vokalisasi (nilai: 01..99)
EDA (Exploratory Data Analysis)
Summary Statistics
untuk menentukan apakah dataset terdapat imbalance atau bias dalam jumlah data dari dataset ini, kami ingin mencari tahu berapa banyak kategori yang terdapat di dalam dataset.
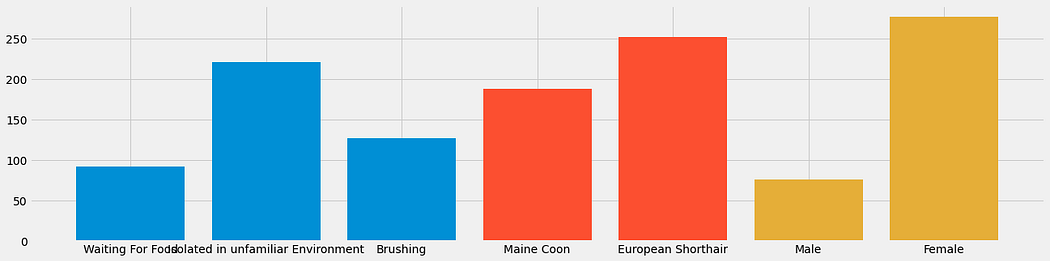
dari hasil yang kita dapat di atas kita mendapatkan kesimpulan bahwa apabila data murni digunakan untuk modelling/klasifikasi akan terdapat bias dari jumlah data kucing yang ada.
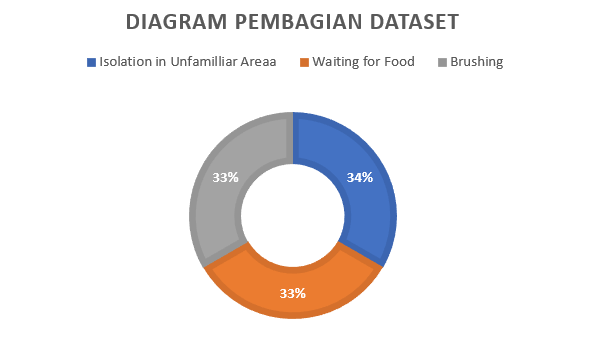
Hal yang pertama dilihat pada data adalah ketidakseimbangan dari jumlah data dimana terdapat 221 jumlah file untuk “Isolation in unfamillar Area”, 91 file untuk “Waiting for Food”, dan 127 untuk “Brushing”.
Dari sana sendiri dapat dilihat bahwa file untuk “Waiting for Food” terlalu sedikit dan jika jumlah filenya terlalu sedikit maka akan terjadi Target imbalance yaitu suatu masalah yang dimana model akan cenderung mengkategorikan prediksi ke dalam class yang memiliki instance lebih banyak.
Audio Length
durasi audio juga merupakan hal yang penting untuk diperhatikan dalam pengklasifikasian data karena durasi audio juga dapat menyebabkan bias dalam data.
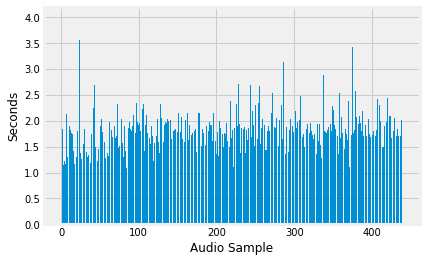
dari hasil yang kita dapat di atas kita mendapatkan kesimpulan bahwa durasi data audio juga tidak merata, sehingga dapat menghasilkan bias.

dari data tersebut kita tahu bahwa rata-rata data meong kucing berdurasi di bawah dua detik dan memiliki beberapa outlier yang berdurasi empat detik.
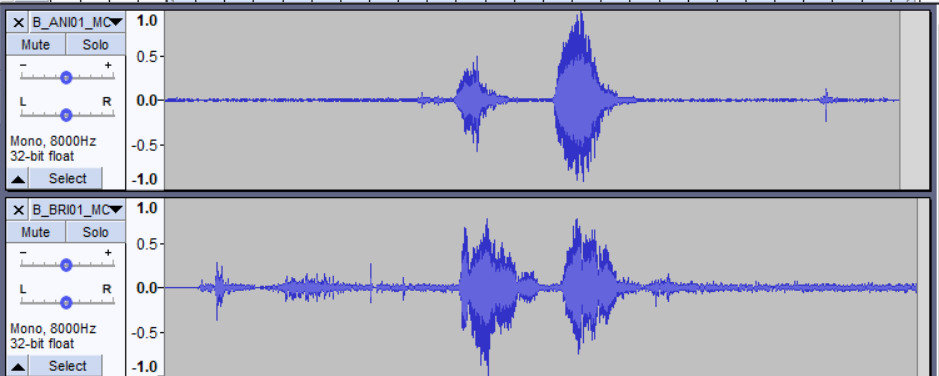
Audio Volume
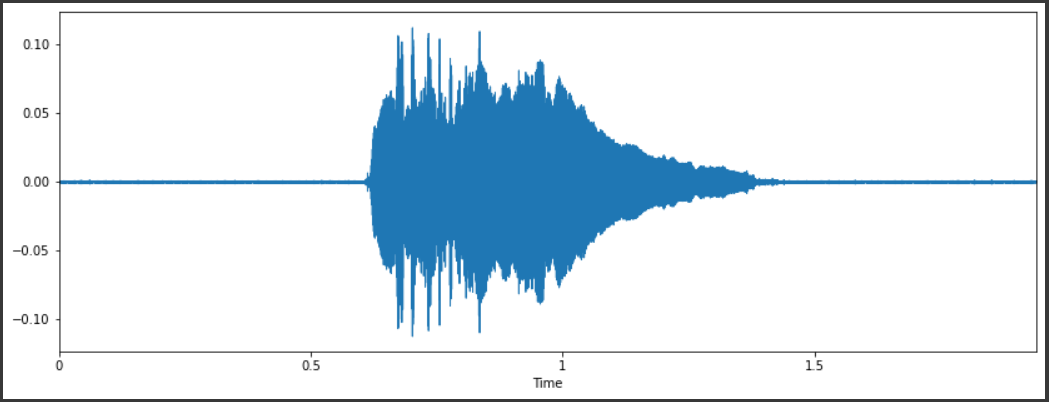
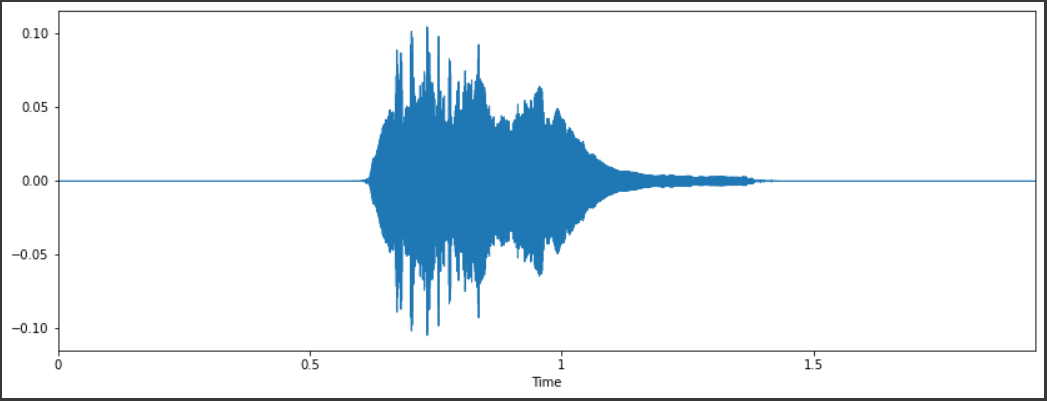
Dalam testing file-file .wav dari dataset terlihat bahwa volume tiap file tidak sama, dan juga kebanyakan dari file memiliki volume yang terlalu kecil untuk dibandingkan. Berikut ini dapat dilihat dua file yang berbeda pada folder sama.
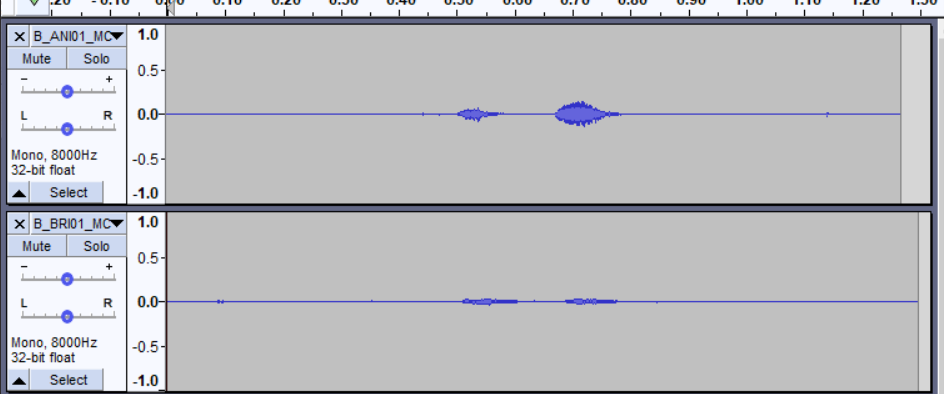
Dari sini dapat dilihat bahwa amplitudo wave graph kedua file berada dibawah 0,5 yang terlalu kecil untuk dipakai dalam model. Dan juga dapat dilihat bahwa file kedua (bawah) memiliki amplitudo yang rata-rata lebih kecil dibanding file pertama (atas) yang nantinya juga akan pengaruh ke dalam pembuatan model.
Sample rate rendah
Sample rate menunjukkan seberapa banyak poin data digital yang diambil atau dikumpulkan dari sebuah sinyal audio elektris yang mengalir. Dengan kata lain, seberapa banyak poin digunakan untuk membentuk kembali sound yang kita dengar.
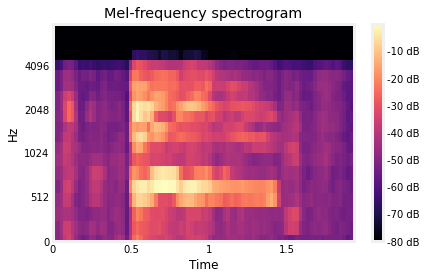
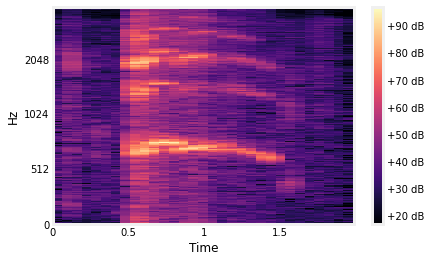
Kami memeriksa sample rate dataset dan mendapati semua file audio memiliki sample rate bernilai 8,000 Hz. Hal ini berarti akan ada 8000 sampel tiap detiknya. Besar sample rate kami rasa terlalu kecil karena setelah melakukan riset, pada masa kini, standar audio modern sudah berbesar minimal 22,050 Hz. Dengan demikian, kami akan menaikkan sample rate dari dataset audio kami.
Preprocessing Data
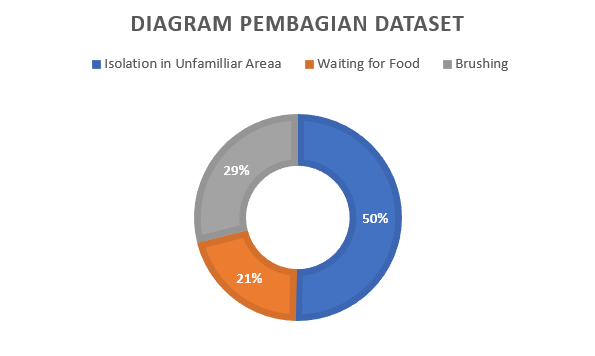
- Pengurangan data kerena jumlah tidak seimbang (221 I, 92 F, 127 B)
Solusi dari permasalahan ini adalah untuk mengurangkan data yang terlalu berlebihan yaitu pada “Isolation in Unfamilliar Area”. Setelah dilihat dataset “Isolation in Unfamilliar Area” terlihat bahwa suara kucing yang sama lebih banyak dibandingkan dataset “Brushing” dan “Waiting for Food” kemungkinan besar karena kedua dataset tersebut lebih susah diambil recording dibandingkan “Isolation in Unfamilliar Area”. Dari sana kami mencoba untuk meratakan dataset dimana sekarang “Isolation in Unfamilliar Area” berjumlah 87, “Brushing” 87, “Waiting for Food” 87 sehingga pembagian dataset akan lebih sama rata.
- Suara terlalu kecil, dan tidak seimbang satu sama lainnya
Solusi dari suara yang terlalu kecil adalah untuk me-normalize .wav filenya, dimana rata-rata amplitudo akan dinaikan ke suatu rata-rata tertentu, dimana disini rata-ratanya adalah 1.
Normalize dilakukan dengan menggunakan library AudioSegment dan Effects dari package pydub.
! pip install pydubDi mana kami membuat function yang mengubah file yang belum ter-normalize menjadi normalize, dan nanti outputnya akan men-overwrite file yang belum di normalize. Setelah itu tinggal di loop file-file yang berada pada folder test dan train.
- Membersihkan noise pada audio
Jika kita amati waveform dari audio pada dataset, kita bisa melihat adanya noise yang bukan merupakan bagian utama suara kucing. Noise ini berpotensi memicu kesalahan interpretasi pada model. Dengan demikian, pada tahap ini, kita akan melakukan noise reduction pada file audio untuk meminimalisasi kesalahan tersebut.
Noise reduction dapat dicapai dengan bantuan library noisereduce. Sesuai dokumentasinya, kita perlu menginstall dan meng-import library tersebut dengan kode sebagai berikut
!pip install noisereduce import noisereduce as nrUntuk menjalankannya, kita membutuhkan bantuan library lain, contohnya wavfile atau librosa untuk memuat file audio.
- Mengubah channel ke mono
Terdapat dua jenis channel audio, yaitu mono dan stereo. Ketika kita mengekstrak digital value dari sebuah audio, channel mono akan menghasilkan data berukuran satu dimensi, sedangkan channel stereo akan menghasilkan data multidimensi. Perbedaan ini perlu memastikan dan menyamakan ke salah satu channel, yaitu channel mono karena data satu dimensi lebih mudah dikelola oleh model.
Untuk mencapai hal tersebut, kita dipermudah dengan bantuan library librosa pada method load. Secara default, method load tersebut memiliki parameter mono yang bernilai True sehingga audio apapun yang di-load akan dikonversi ke channel mono.
import librosa data, sample_rate = librosa.load(file_path, mono=True) # parameter mono opsional karena secara default bernilai True- Meningkatkan sample rate ke 22050
Setiap file audio bisa memiliki sample rate yang berbeda-beda. Sample rate akan berpengaruh pada tahap ADC (Audio to Digital Converter). Dengan demikian, kita perlu menyamakan sample rate semua file audio. Hal ini bisa dicapai dengan bantuan library librosa pada method load. Secara default, method load ini memiliki parameter sr (sample rate) yang bernilai 22050.
import librosa data, sample_rate = librosa.load(file_path, sr=22050) # parameter sr opsional karena secara default bernilai 22050Modelling
Tensorflow Keras Sequential
Kami memakai konsep mfcc untuk mengekstrak informasi audio. MFCC sendiri merupakan Mel-frequency cepstrum, yaitu representasi cepstrum sinyal audio pada mel spectogram. Cepstrum ini dapat diperoleh sebagai berikut:
- Sinyal audio ditransformasi oleh DFT (Discrete Fourier Transform) untuk memperoleh grafik spektrumnya
- Mengaplikasikan logaritma pada grafik dikarenakan kita tidak menerima intensitas suara secara linear, namun logaritmik.
- Mel-scaling, yaitu mengonversi linear frequency representation sebelumnya menjadi mel based representation
- Menerapkan inverse fourier, salah satu penerapannya yang terkenal adalah discrete cosine transform dikarenakan beberapa keuntungannya seperti simplifikasi dan outputnya yang berupa nilai real.
- Akhirnya, kita akan memperoleh MFCC sebagai nilai-nilai yang membentuk timbre / menunjukkan informasi dasar dari spektrum
Pada dasarnya, kita mencari spektrum dari spektrum. Hal ini disingkat dengan istilah cepstrum.
Model sequential-nya sendiri menggunakan empat layer di mana tiga layer menerapkan activation ‘relu’ untuk membatasi kembalian nilai tidak negatif nilai serta layer terakhir menggunakan activation ‘softmax’ untuk mengembalikan probalitas prediksi.
Model juga menerapkan dropout 0.5 untuk menghindari overfitting.
model.compile(loss='categorical_crossentropy',metrics=['accuracy'],optimizer='adam')Model ini dikompilasi dengan:
- Loss categorical_crossentropy sebagai fungsi keputusan jika terjadi perbedaan prediksi. Fungsi loss ini cocok untuk dataset kami yang menerapkan one-hot encoding pada label
- Metrics accuracy yang akan mencocokan seberapa sering prediksi oleh model benar terhadap label pada dataset
- Optimizer adam sebagai optimasi populer untuk neural network yang efisien dan menggunakan sedikit memori serta cocok untuk dataset kami yang berukuran cukup besar.
Untuk fitting model, kami mencoba mengonfigurasi kombinasi batch_size dan epochs terbaik untuk model. Pada akhirnya, kami menemukan kombinasi batch size 32 an epochs 33 memberikan hasil terbaik.
Tensorflow Lite Model Maker
Untuk pembandingan model utama kita disini menggunakan tensorflow model maker sebagai pembandingnya.
- Pertama kita membuat spesifikasi model, disini kita membuat base spesifikasi dari model kita yang nantinya akan buat menggunakan YamNet, YamNet itu sendiri merupakan suatu audio event classifier yang membuat spesifikasi jenis event audio yang berlangsung berdasarkan paramater ontology AudioSet secara general, dengan menggunakan YamNet tersebut kami dapat meningkatkan akurasi dari model itu sendirinya.
Di sini kami menggunakan parameter keep_yamnet_and_custom_heads untuk menggabungkam sample yamnet dengan model sekarang. Lalu kita mengkalsifikasi frame_step yaitu jarak antar audio dan frame_length yaitu panjang satu audio file.
- Selanjutnya kita me-load data pada folder train dan test dengan spesifikasi spec. Dan juga kita split 30% data train yang nantinya digunakan sebagai data untuk memvalidasi agar tidak terdapat data outlier.
- Terakhir adalah bagian pemodelannya sendiri dimana kita menset batch size menjadi 64 dengan 32 iterasi (epochs) dan lalu langsung mengcall fungsi dari model maker yaitu audio_classifier yang mengambil train data yang telah di load berdasarkan spec, validation_data dari train_data, serta batch size dan epochs. Dimana fungsi ini sendirinya akan mengolah data berdasarakan pemodelan audio Sequential.
Report Hasil Model
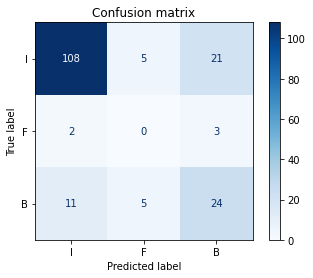
Dengan menggunakan model Sequential, akurasi terbaik yang bisa didapatkan sebesar 74,57%. Dengan confusion matrix, hasil dapat divisualisasikan sebagai berikut
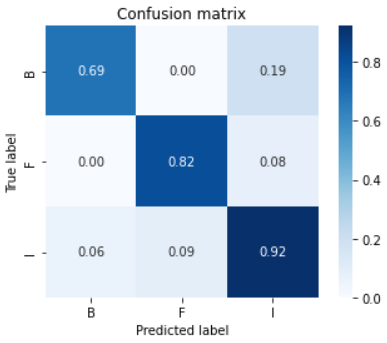
Untuk model menggunakan tensorflow lite model maker, akurasi terbaik yang dicapai adalah 83,01% dengan loss 63,19% dimana confusion matrix-nya berbentuk seperti ini
Untuk output yang lebih detail kita menggunakan library serving model dari tensorflow yang dimana bisa kita lihat klasifikasi event dari YamNet serta dari custom model kita sebagai berikut:

Data yang dipakai adalah kucing brushing dan modelnya memprediksi secara benar



Comments
Post a Comment